정규식을 이용하면 문자열 처리를 보다 다양하고 간편하게 처리할 수 있다는 것을 알아 보았다.
ANSI 코드 문자열을 Unicode 문자열로 변환하기 위해서는 "xxx" -> _T("xxx") 로 치환해 주어야 한다.
전처리기 _T(x) 는 다음과 같이 정의되어 있다.
#define _T(x) __T(x)
#define _TEXT(x) __T(x)
#ifdef _UNICODE
#define __T(x) L ## x
#else
#define __T(x) x
#endif
#define _TEXT(x) __T(x)
#ifdef _UNICODE
#define __T(x) L ## x
#else
#define __T(x) x
#endif
_UNICODE 이면 L"xxx"로 치환,
_UNICODE가 아니면 "xxx"로 치환.
그렇다면 단순히 "xxx"를 찾아서 _T("xxx")로 치환해 주면 간단히 유니코드를 지원하는 문자열이 된다. ("말이 쉽지 어느 세월에 다 바꾸냐?" 하고 생각하시는 분들은 아랫글을 봐 주세요. ^^; )
그래서 짜잔!! 정규식의 활용 2번째. 말이 길어지면 지루해지는 법. 결과부터 볼까요?
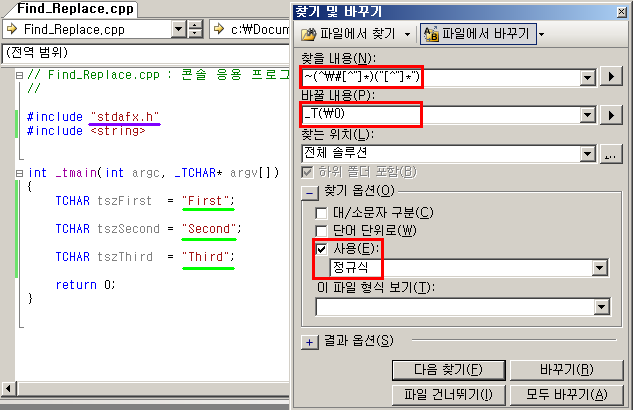
왼쪽의 소스코드에는 "xxx" 와 같은 문구가 4번 등장한다.
- #include "stdafx.h" 보라색 밑줄
- main() 안의 초록색 밑줄
그리고 오른쪽의 바꾸기 탭에 "찾을 내용"과 "바꿀 내용" 그리고 찾기 옵션의 정규식 부분을 잘 보자!
찾을 내용 : (#으로 문장이 시작되고, "를 만날때까지)를 무시하고, ("로 시작해서 "가 아닌 문자열들을 포함하고 "로 끝나는 부분)을 찾는다.
~(^\#[^"]*)("[^"]*")
바꿀 내용 : \0 위에서 파란색 괄호에 둘러쌓인 부분을 선택하고, 앞에는 _T(를 붙이고 뒤에는 )를 붙인다.
_T(\0)
이렇게 전체 바꾸기를 수행한 다음 결과를 보도록 하자.
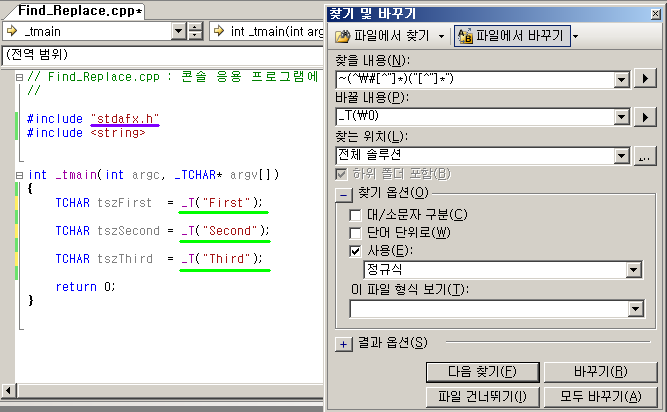
위와 같이 #으로 시작하는 "xxx" 부분(보라색 밑줄)은 바뀌지 않았고,
#으로 시작하지 않는 "xxx" 부분(초록색 밑줄)이 _T("xxx")로 치환 되었다.
MSDN 참조 : http://msdn.microsoft.com/ko-kr/library/aa293063(VS.71).aspx
http://msdn.microsoft.com/ko-kr/library/2k3te2cs(VS.80).aspx
덧글을 달아 주세요
비밀방문자 2009/04/03 17:32 고유주소 고치기 답하기
관리자만 볼 수 있는 댓글입니다.
TTF 2009/04/04 15:42 고유주소 고치기
제 블로그의 자료는 언제나 퍼가셔도 좋습니다.
블로깅을 하고 퍼가지 못하게 하려면, 비공개로 글을 작성했을테니까요.
그리고 출처 남겨 주신것은 감사드립니다.